
Jupyter notebookというとブラウザから開くというイメージがありますが、
統合開発環境のプラグインを使うということもできるというお話です。
VS CodeではPCにあるカーネルを自動で検索してくれるので、
そのプロジェクトに使うカーネルをVS Code上で選択することができます。
VS CodeでもJupyter notebookを手軽に使えるね
Jypyter notebookはデータサイエンス系の人がよく使うパッケージで
これらのファイルは「ipynb」という拡張子が付いています。
VS Codeでは普通にプロジェクトからipynbファイルを開くだけで自動的に使えます。
これはAnacondaがChomeなどのブラウザ上で動かすのと比較すると、
ひとつの開発環境上でいろいろといじることができるという意味で良いですよね。
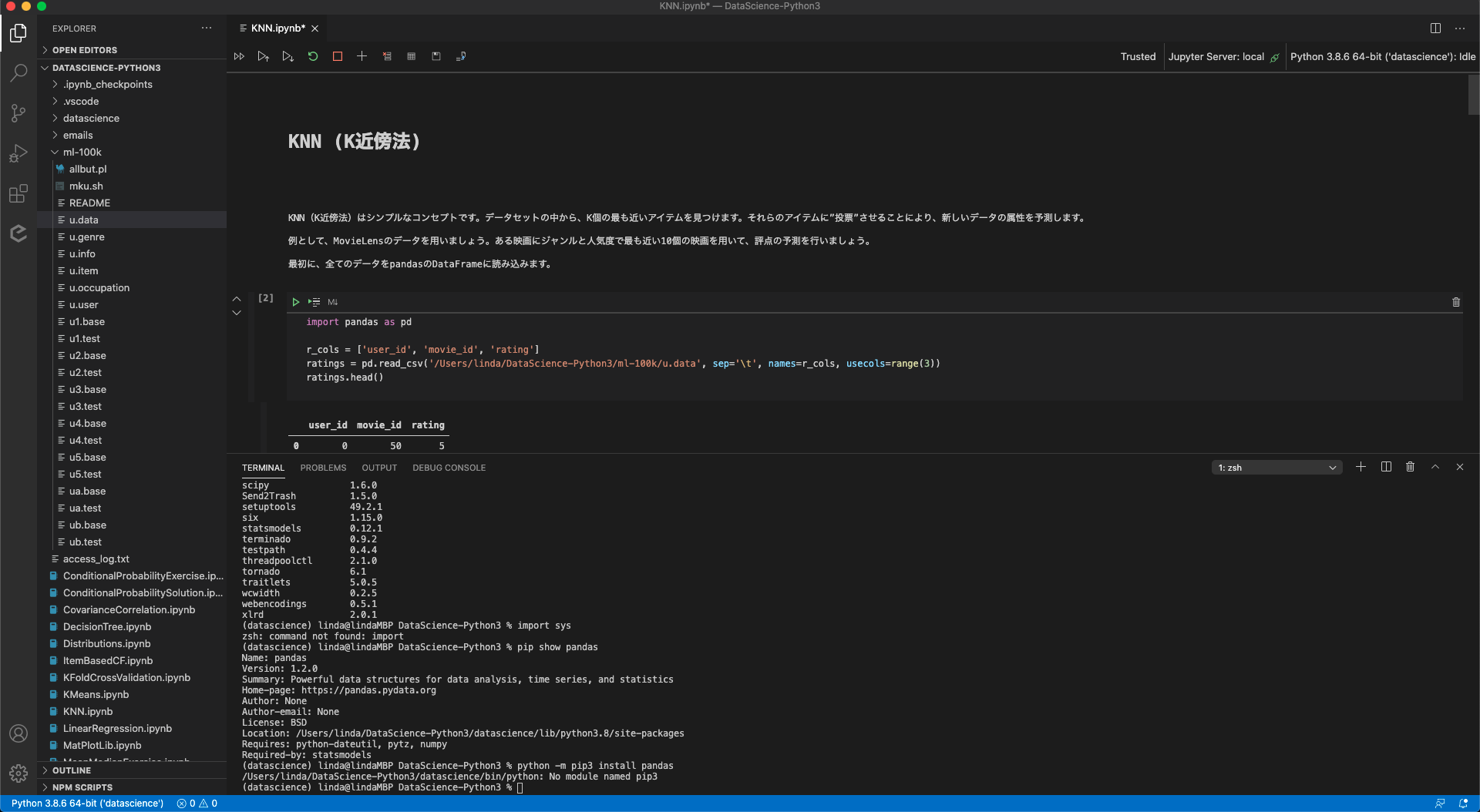
カーネルの設定は左上に出てくるところで選択することができます。
今回は環境をプロジェクトのフォルダ内に作成し、カーネルとして選択しました。
このカーネルについてはローカルのものでも仮想環境上のものも使えますが、
当然ながら必要なパッケージをインストールしている開発環境でなければなりません。

なおVS Code上でのJupyter notebookの操作については以下のサイトが参考になります。
[VS Code Python拡張] データサイエンスチュートリアルをやりながらVS CodeでのJupyter Notebookの使い方をマスターする | Developers.IO
venvって何?Python3用の環境管理を行うツール
今回なぜvenvを使ってデータサイエンスをしようとなっているのか。
プログラマの皆様は既にご承知置きのことではありますが、
昔の私のような始めたばかりの人が少しでも迷わないように少し前置きを書かせていただきます。
今回は「venvというツールを使ってデータサイエンスをする環境を作る」わけですが、
なぜこうするかというと、私はdjangoの開発環境をローカルに構築しているため、
なるべくデータサイエンスの開発環境と分けて使いたかったからです。
何を言っているかよくわからないという場合はとりあえずあまり気にしないで下さい。
venvを使うとPython3で用途に応じて専用の実行環境を作成することができます。
その利点を生かして、今回のようにデータサイエンス演習用プロジェクトフォルダ内に、
改めて開発に必要なPython3とパッケージをインストールして行きます。
本当に初めてデータサイエンスをしてみたいと思ったという方は、
シンプルにローカル環境にPython3をインストールして、
pip installで必要なパッケージを導入するのをおすすめします。それで変になることはほぼありません。
データサイエンスしかやらないのであれば、そして少し開発もしたい!
という程度であればAnacondaもおすすめできるところもあります。
ただし、UNIXコマンドがある程度わかって使えるレベルならそこまでおすすめはしません。

ほぼ準備不要!venvの仮想環境を作成する方法
前置きは長くなりましたが、個人的にPythonを使う雑食系のエンジニアであれば、
仕事や開発に使う環境とデータサイエンス環境、新しいフレームワークを使う個人開発環境、
この3つくらいの仮想環境を念頭においても良いと思います。
venvはプロジェクトフォルダ内に仮想環境を作っておくことで、
毎回、それぞれの作業をするときは専用の仮想環境で開発をスタートすれば、
仕事や別プロジェクトの開発環境に影響を与えずにスムーズに開発ができるでしょう。
というわけで今回はvenvで専用の開発環境を作りましょう。当然ですがPython3を使います。
Macならターミナルに以下のコマンドを入力してみましょう。($は入力しないでOK)
$ python --version
Python 3.7.4
$ python2 --version
Python 2.7.16Python –versionで最初からPython3.X.Xが表示されれば既にローカルでPython3が使えます。
python3 –versionでPython3.X.Xが表示されればpython3コマンドでPython3が使えます。
どちらでもOKですが、Python2しか使えない場合はPython3を導入しておきましょう。
venvはPythonで最初から使えるツールなのでPython3をインストールしていれば、
そのままvenv環境を作ることができます。
次に、プロジェクトフォルダを作成しましょう。
cd (プロジェクトフォルダに移動)
python3 -m venv datacdコマンドはフォルダ移動に使えるコマンドです。
cdを使ってPCのいろんなフォルダに移動することができます。
今回はプロジェクトフォルダ内にvenvの環境も作ってしまうので、
例えば自分のルートディレクトリ(ユーザー名のフォルダ直下)に新しいフォルダを作成して、
そこにコマンドを使って移動しておきましょう。
cd (このコマンドだけでルートディレクトリに移動します)
touch DataScience
cd DataScienceフォルダをどこに作成するかは自由なのですが、
自分のユーザー名のフォルダ直下がわかりやすいので皆さんそこに設定することが多いです。
この場合は/Users/(人によって違うユーザー名)/DataScienceに移動しましたね。
python3 -m venv dataそのフォルダ内で上のコマンドを入力すると、自動的にvenvの仮想環境ができます。
今回はデータサイエンス用の仮想環境なのでdataという名前にしました。
仮想環境を起動するにはsoueceコマンドを使って毎回起動しなければなりません。
ターミナルを一度消してしまうと仮想環境も終わってしまうことがありますので、
毎回、VS Codeのターミナル上で仮想環境を起動するようにしましょう。
source data/bin/activate
(data) linda@lindaMBP DataScience %ちゃんと仮想環境が起動していれば(data)といったように、
行の最初にその仮想環境名のカッコがついたコマンドラインになります。
これでvenvを使ってDataScienceフォルダにdataという仮想環境を作成できました。
sourceコマンドでdataという仮想環境を起動することも確認できましたね。
必要なパッケージは必ず仮想環境内でpipを実行!
ある程度知っている方には蛇足的な説明になりますが、
仮想環境を作ったということは、ローカルや別の名前の仮想環境とは別の開発環境です。
つまり、どちらかでパッケージをインストールしても別の環境とは連動していません。
もし、あなたが開発に慣れていないエンジニアである場合は、
必ずプロジェクトを始める前に自分が利用したい環境を使っているかチェックしましょう。
例えば、先程venvで作成したdataという仮想環境はPython3の機能を使っているので、
当然Python3が使えますがパッケージは最初から入っていませんので一つずついれていきます。
パッケージというのは、モジュールの集合体です。
と言ってもわからないと思いますが、シンプルに.pyファイルをモジュールと言います。
.pyファイルはPythonで記述されたプログラムのソースコードですから、
パッケージというのは「.pyファイルで何らかの機能を果たすために作られたまとまり」です。
例えばデータサイエンスでよく使うパッケージといえばpandasがあります。
このパッケージををインストールするには、このようになります。
pip install pandasこのpip installコマンドでパッケージを指定することで初めて必要なパッケージが使えます。
パッケージは他のパッケージを利用するものがほとんどですから、
例えばpandasをインストールすると、numpyなどの他のパッケージもインストールされます。
インストールする際はvenvなどの仮想環境を用いる際は、
必ずコマンドラインの頭に()がついているか確認します。これが仮想環境の証です。
その上でpipコマンドをつかってパッケージをインストールしましょう。
参考にしたサイト
Jupyterで複数カーネルを簡単に選択するための設定
https://qiita.com/tomochiii/items/8b937f15c79a0c3eae0e
環境
Machine:Macbook Pro 2013 Late,
OS:Catalina 10.15.7
Python3.7.4